AI Slop: Bug or Feature? What Philosophy of Science Taught Me
By Amin Rabinia · Founder, Glissando AI

You've seen it. An AI image that's technically flawless — the lighting is perfect, the textures are crisp, the composition is clean. And yet something is wrong. You can't name it. But you feel it in the first second.
This isn't a bug. It's not going away with the next model update. And the explanation isn't technical — it's philosophical.
The Problem Has a Name Now
Merriam-Webster named "slop" its Word of the Year for 2025 — defined as "digital content of low quality produced in large quantities by AI." YouTube has been inundated with lazy AI-generated footage, from pseudo-educational videos aimed at toddlers to fake movie trailers. Some channels are now explicitly labeling themselves "no AI" as a way to signal authenticity to exhausted viewers.
Shrimp Jesus — a surreal AI-generated image of Jesus formed from shrimp — became probably the best-known symbol of AI slop. It went viral not because it was convincing but because it was bizarre in a very specific way. Too detailed. Too smooth. Wrong in ways that are hard to articulate.
That wrongness is what I want to explain.
A Philosopher Saw This Coming — in 1999
Paul Feyerabend was an Austrian philosopher of science who spent his career arguing against one idea: that our theories of reality are reality.

In Conquest of Abundance, his final book, he made a simple but radical claim — "reality is always larger than any model we build to describe it." Science is not wrong. It's just a slice. A useful, powerful slice. But no matter how precise your theory gets, reality keeps exceeding it. It's infinite. Models are not.
He wasn't talking about AI — the book came out the year he died. But he was describing exactly what's happening with every AI-generated image you've ever spotted as fake.
The Model Is a Slice
A generative AI model is trained on data. Enormous amounts of it — billions of images, videos, text descriptions. But even billions of images is a fraction of the visual reality that has ever existed.
What was never photographed doesn't exist inside the model. The specific quality of afternoon light in a particular village in Portugal in 1987. The way your grandmother's kitchen smelled and what it looked like at 6am. The ten thousand micro-variations in how a specific person laughs.
None of that is in the training data. It was never captured. So the model has no access to it. It works only with what humans chose to document, upload, and label — which is itself already a heavily filtered, culturally biased, incomplete record of reality.
Feyerabend would call this obvious. Every model of reality leaves most of reality out. That's what makes it a model.
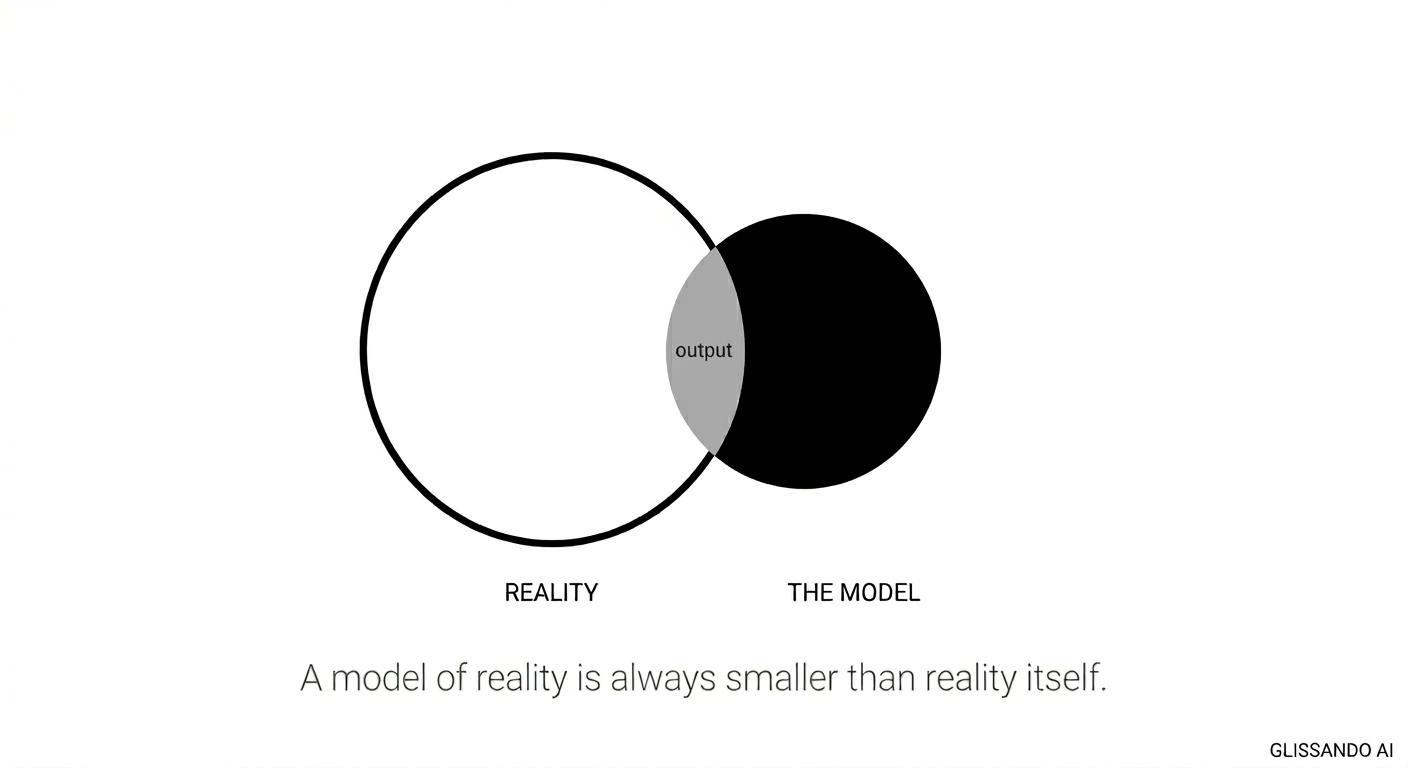
The output lives only in the overlap. Reality is always bigger than the model.
The Prompt Is Also a Slice
Now add a second problem. When you generate an image, you guide it with a prompt. A sentence or two. Maybe a paragraph if you're thorough.
"A cozy coffee shop in Paris on a rainy morning, warm lighting, film grain."

This is what that prompt generates. Beautiful. And instantly recognizable as not real.
That description points at something real — or something you imagine as real. But the description itself is a tiny fragment of what you actually mean. You have a feeling, a memory, a specific vision. The prompt captures maybe 5% of it. The rest stays in your head.
So you have a model that only knows a fraction of reality, being guided by a prompt that only expresses a fraction of your intent.
Both the source and the guide are limited. The output can't be anything other than limited too.
Generation Is Averaging, Not Perceiving
Here's what actually happens when you hit generate.
The model doesn't see. It doesn't perceive. It finds the statistical center — the weighted average of everything it has seen that resembles what your prompt seems to be asking for. It produces the most likely version of your request, given its training.
That's genuinely impressive engineering. But "most likely" and "real" are not the same thing.
Real things are specific. They have history, accident, particularity. The coffee cup on your desk has a chip on the rim from when you dropped it in 2019. The light coming through your window is slightly different today than yesterday. Real is full of irreducible detail that has no average.
Averages are smooth. Averages are generic. Averages are what AI generates — and we feel that the moment we look.
When you look closely at AI-generated content, you find inconsistencies: textures that are flat when they shouldn't be, patterns that are too perfect, or details that are inexplicably off. Shadows don't fall naturally. Lines don't follow perspective correctly. These aren't random errors. They're the fingerprints of averaging. The model produced what was statistically expected, not what was physically real.
This Is Structural, Not Fixable
The natural response is: better models, more data. And that will help. Images have gotten dramatically more convincing in two years. Video is catching up fast.
But Feyerabend's point holds at any scale. More training data is still finite training data. A more detailed prompt is still an incomplete description of intent. The gap between model and reality doesn't close — it just gets smaller.
As of March 2026, NewsGuard had identified over 3,000 AI content farm sites, with numbers more than doubling over the previous year. The volume is increasing while the gap remains. We're getting more slop, not less fake-feeling slop.
The only way to close the gap completely would be infinite training data and a perfectly complete description of intent. Neither is possible. So the uncanny valley isn't a temporary phase on the way to perfect AI realism. It's a permanent feature of how these systems work.
What This Means Practically
If you're building with AI-generated content — images, video, copy — this is worth internalizing.
The output is the average of a slice. It's not reality. It's the model's best approximation of your prompt's approximate intent. That's useful. It's just not the same as something made by a person who perceived the real thing and made choices about how to represent it.
The images that fool us most are the ones that aren't trying to be realistic — abstract art, fantastical scenes, things that have no real-world reference. There's no reality to compare them against. The averaging doesn't show.
The images that feel most fake are the ones reaching hardest for the real. A portrait. A news photo. A scene from everyday life. Those are exactly the cases where the gap between the model's slice and actual reality is most visible — because we know what the real thing looks like.
Feyerabend spent his career arguing that our maps are not the territory. AI is the most sophisticated map-drawing machine ever built. But the territory is still bigger.
Amin Rabinia is the founder of Glissando AI. He holds an MA in Philosophy and an MS in Computer Science.
Thinking clearly about what AI can and can't do is where good strategy starts. Explore AI Strategy Consulting →
Get the next one in your inbox
One practical AI idea per week, from real client projects. No fluff, unsubscribe anytime.